Normally, a company using Solr to power it's search engine will have a front end written in a web framework such as Ruby on Rails that makes calls to Solr through it's REST interface. One example is Zvents.com (my employer), where our front end is RoR that makes multiple calls to Solr to power various portions of the site. One common problem we encountered at Zvents was that a particular search would yield weird results and we'd execute the query passing the "&debugQuery=true" flag to study why that result appeared where it did. Afterwards; however, came the hard part.. tuning the ranking functions and refreshing the page to see if the results look better. There are two ways to do this:
- Pass the modified set of ranking function parameters (bf, pf and/or qf) to Solr via the URL string
- Modify solrconfig.xml and restart Solr to see what the results look like.
While #1 is certainly better than #2, both have their problems for the following reasons:
- Restarting Solr can be slow and is not scalable. Each change requires a restart and this may take several minutes just to see the changes. Also it forces the person doing the tuning (say the search scientist/expert) to be able to understand the operational side (i.e. where Solr resides, how to restart it etc). This may be problematic for some people who are a averse to dealing with such operational details.
- While passing the ranking function parameters via the URL works, it makes the URL significantly longer (which is a personal annoyance that most browsers have single line URL boxes) and this doesn't allow you to see the results of your change in the UI built by your front end team (without a special interface or requiring someone from that team to make changes to the UI code).
At Zvents, our initial solution to this involved building a special UI hosted within the Solr web application context, a JSP page + corresponding servlet with text boxes for each major ranking function parameter (qf, pf, bf) per handler. Our search experts would access this page and make the necessary changes which, upon submission of the form, would update the respective Solr handler's in-memory configuration map and thus the changes could be viewed in the UI built by our front end team. This was a great solution and certainly works; however, when Solr introduced JMX, it made more sense that such functionality live inside an MBean that exposed the ability to change these parameters using JConsole or any other UI with similar functionality.
Solr 2306- Modify default solrconfig parameters via JMX
When Solr added JMX support, it was a great way for administrators to be able to use a well known set of tools to understand what is going on inside of the JVM running Solr. Not only can you use JConsole to understand what the VM is doing but also what is going on inside of Solr.
This patch extends the built-in JMX support to also allow the default parameters (exposed via the <lst name="defaults">) to be exposed as modifiable attributes. When these parameters are modified, the changes are immediately noticed upon the issued search query without requiring any core reloads. To use this patch, follow the steps below and post any questions/comments on this JIRA issue https://issues.apache.org/jira/browse/SOLR-2306.
Step One: Checkout Solr, apply patch and build
svn co http://svn.apache.org/repos/asf/lucene/dev/trunk solr_trunk
cd solr_trunk
patch -p0 < <PATH_TO_PATH>/tuning_patch2.patch
Step Two: Setup and run example Solr instancecd solr
ant dist
cd exampleStep Three: Load sample data
cp ../dist/apache-solr-4.0-SNAPSHOT.war webapps/solr.war
java -jar start.jar
cd exampledocsStep Four: Launch jconsole!
./post.sh *.xml
jconsole

In JConsole, choose the "MBeans" tab and along the left side, expand "/solr", "browse/", "org.apache.solr.component.SearchHandler", "Attributes". From here, you can select an attribute and change it's value.
Step Five: Modify parameters
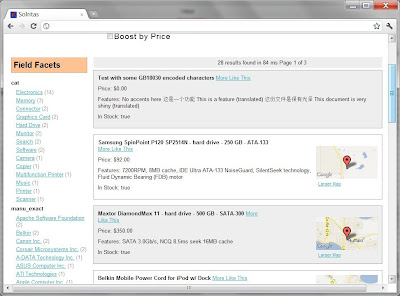
For purposes of demoing the functionality of this patch, let's modify the "fl" parameter which describes the default set of field values to return. This can be overridden by passing &fl= on the URL; however, let's modify this parameter via JConsole to see it's effect. First though, let's look at some data by accessing http://localhost:8983/solr/browse


Conclusion
Step Five: Modify parameters
For purposes of demoing the functionality of this patch, let's modify the "fl" parameter which describes the default set of field values to return. This can be overridden by passing &fl= on the URL; however, let's modify this parameter via JConsole to see it's effect. First though, let's look at some data by accessing http://localhost:8983/solr/browse

Notice that there is at least a name, price, and in-stock fields displayed. Using JConsole (make sure you followed the previous step), select the "fl" attribute and change it's value to only show "score,name"

and refresh your web browser pointing at the browse handler.

Notice that only the name is displayed along the top with the other fields that were initially present no longer there! Try this for other parameters and if you have JConsole pointing at your own search engine, try modifying the qf, pf, and bf parameters to see their effects. Of course keep in mind that to persist the parameter changes, make the appropriate changes in your solrconfig.xml file.
Through a fairly simple, contrived demo using the examples provided in the standard Solr distribution, you were able to change some default handler parameters for a particular search handler and immediately see its effects. Solr's JMX extensions provide a great way to peek inside of a running Solr instance without any major performance impacts. This patch takes this one step further and allows for real-time tuning of a running Solr instance. If you like this patch, and have login credentials on Apache's JIRA, please vote this up to help ensure that it gets rolled into a future release of Solr!